十大经典排序算法–定义及代码实现
排序算法是最基本的算法之一,排序算法可以分为内部排序和外部排序,内部排序是数据记录的内存中进行排序,而外部排序是因为排序的数据很大,一次不能容纳全部的数据记录,在排序过程中需要访问外存。
常见的排序算法有:冒泡排序、选择排序、插入排序、堆排序、归并排序、快速排序、希尔排序、计数排序、桶排序、基数排序;
算法的稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
冒泡排序
冒泡排序的核心思想在于,从第一个元素开始,每相邻两个元素对比大小
如果比较的两个元素前面的一个元素较大,则交换这两个元素的位置
然后再向后移动一个元素再次比较,重复上一个动作
这样完成一个冒泡后,最大的 元素将移动到序列结尾
如图:
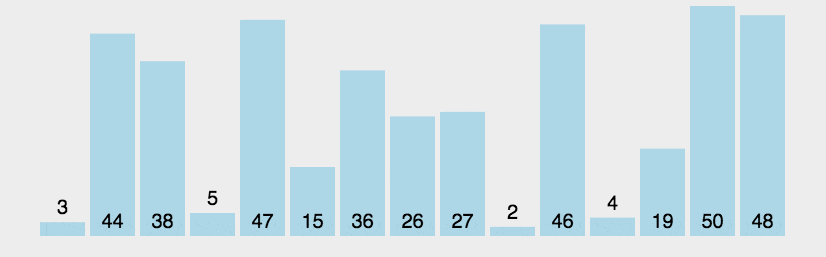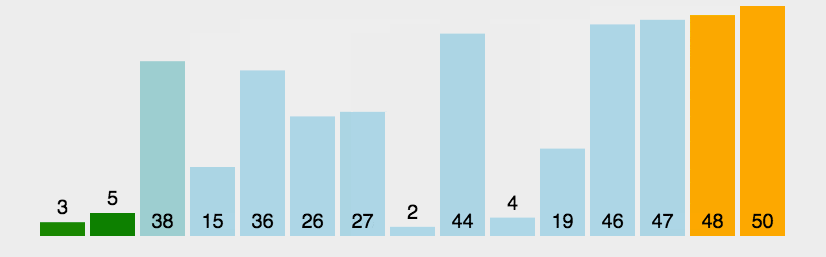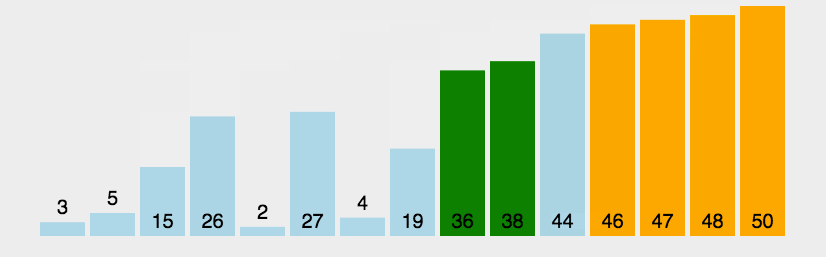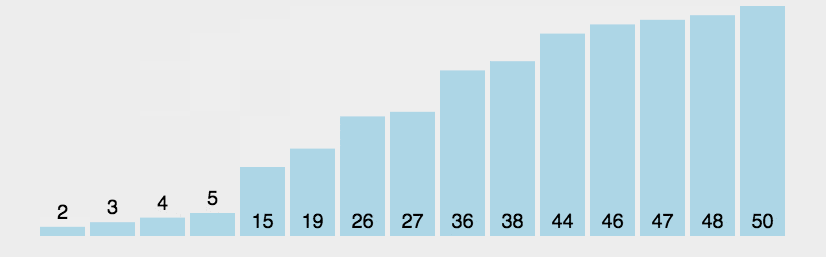
冒泡排序可以加一个状态,如果某次冒泡没有元素移动,则说明已经是目标序列
冒泡排序是一种稳定的排序算法
PHP代码实现:
1 | /** |
选择排序
以最小值为例,选择排序的核心在于,先从无序序列中找出一个最小值,作为第一个值,然后在剩下的无需序列中选出最小值,作为第二个值,依次类推直到所有元素都被筛选完,如图
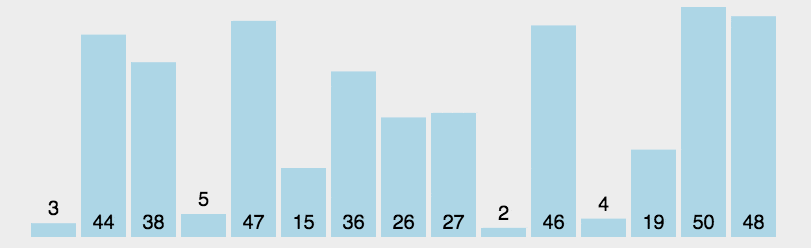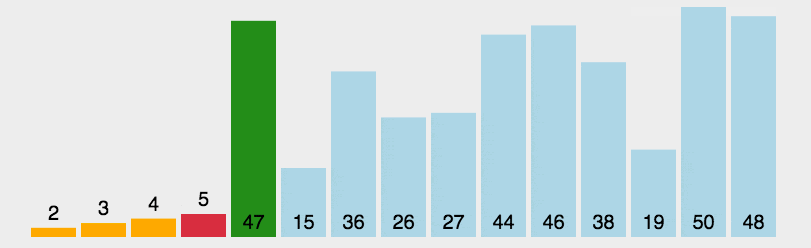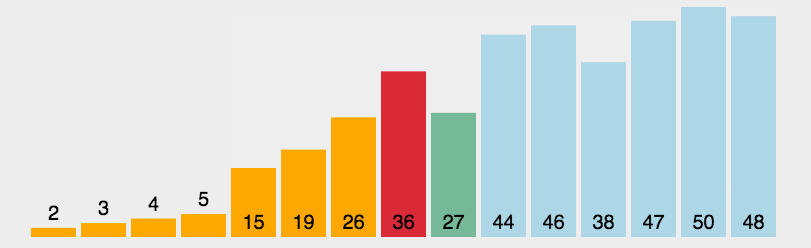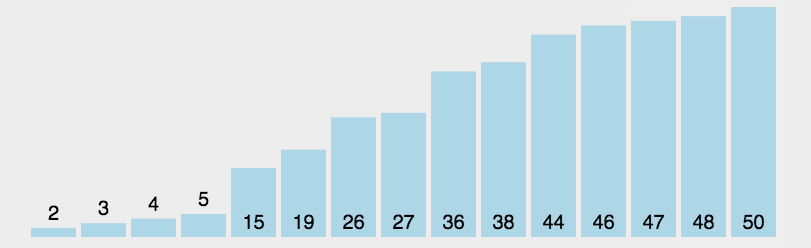
代码实现:
1 | /** |
插入排序
插入排序类似扑克牌排序,是一种最简单直观的排序算法,它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
将序列中的第一个值看作初始的有序序列,然后第二个值到结尾的序列看作无序序列
从头到尾依次扫描无序序列,将扫描到的每个元素插入有序序列的适当位置。
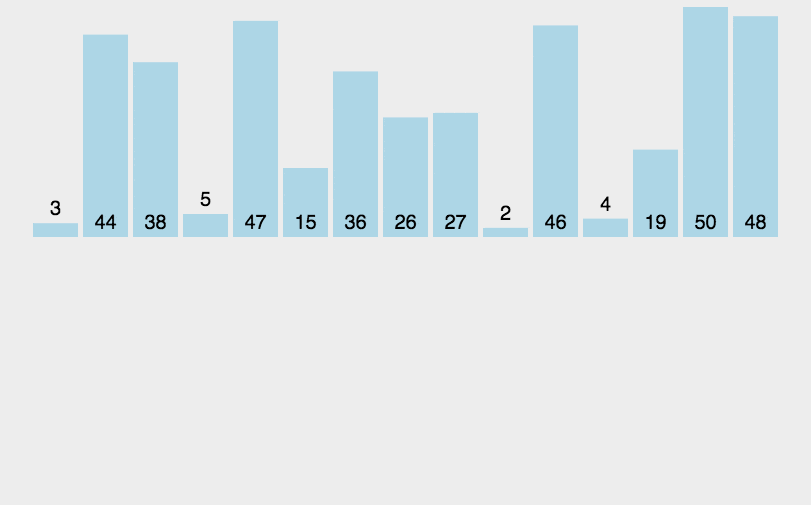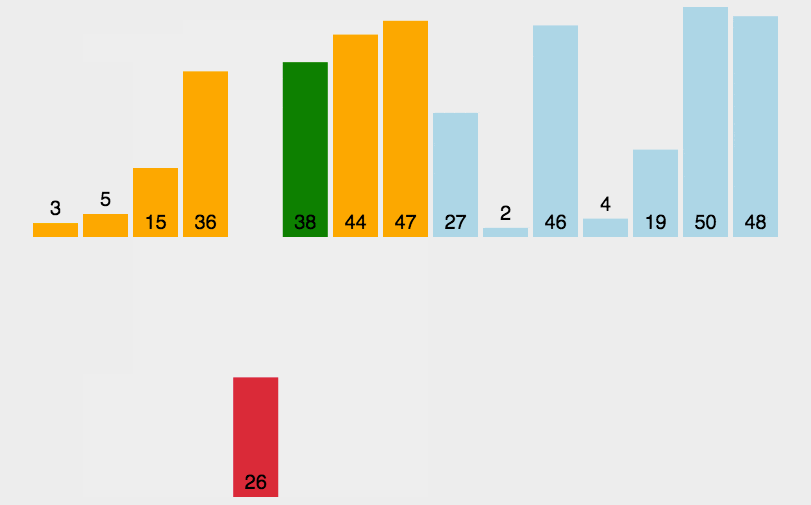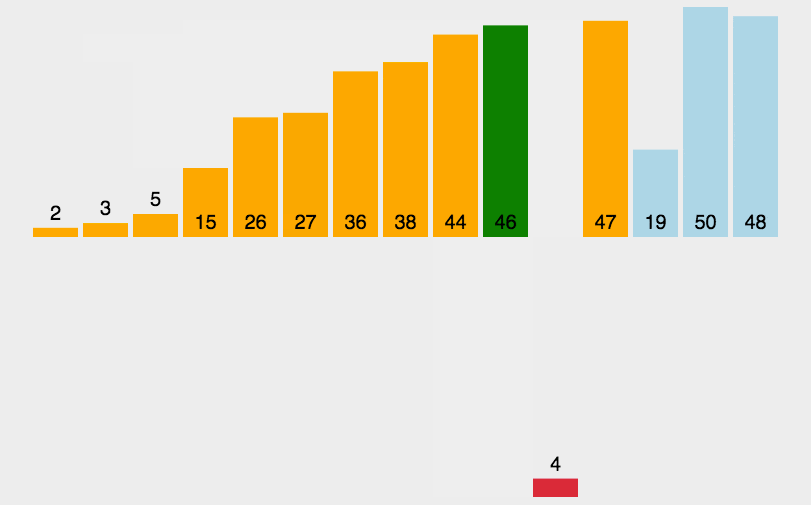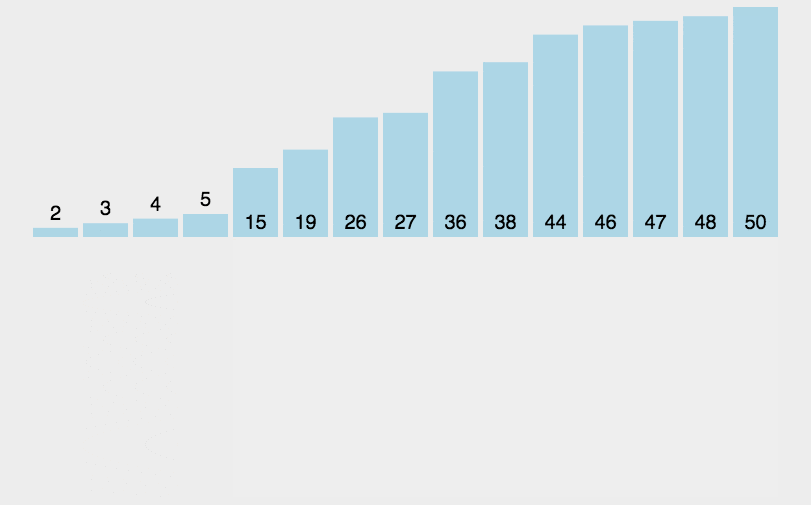
代码实现:
1 | /** |
此处使用foreach 仅仅是为了完成一次对数组的完整遍历,由于插入排序的特性,未循环到的元素都是无序的,已遍历的元素都被归于有序,所有使用foreach遍历实现插入排序效率比使用for循环更高代码更简洁。但其实foreach 循环中遍历的
$arr和 内部排序的$arr是两个变量 ,foreach在循环之初就会建立$arr的一个副本来进行遍历,在循环内部对$arr进行修改时不会影响到foreach创建的副本,因此在其他排序方法中使用foreach可能会出现问题
希尔排序
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是不稳定的(会改变相同元素的顺序)。
希尔排序是基于插入排序改进而来,它基于插入排序的两大特点:
- 插入排序对于几乎已经排好的序列效率较高,可以达到线性排序的效率;
- 但插入排序一般来说是低效的,因为一次只能将数据移动一位;
希尔排序的思想是:先将整个待排序的记录序列分割为若干子序列,待整个序列中的记录“基本有序”时,再对全体记录依次进行直接插入排序
算法步骤:
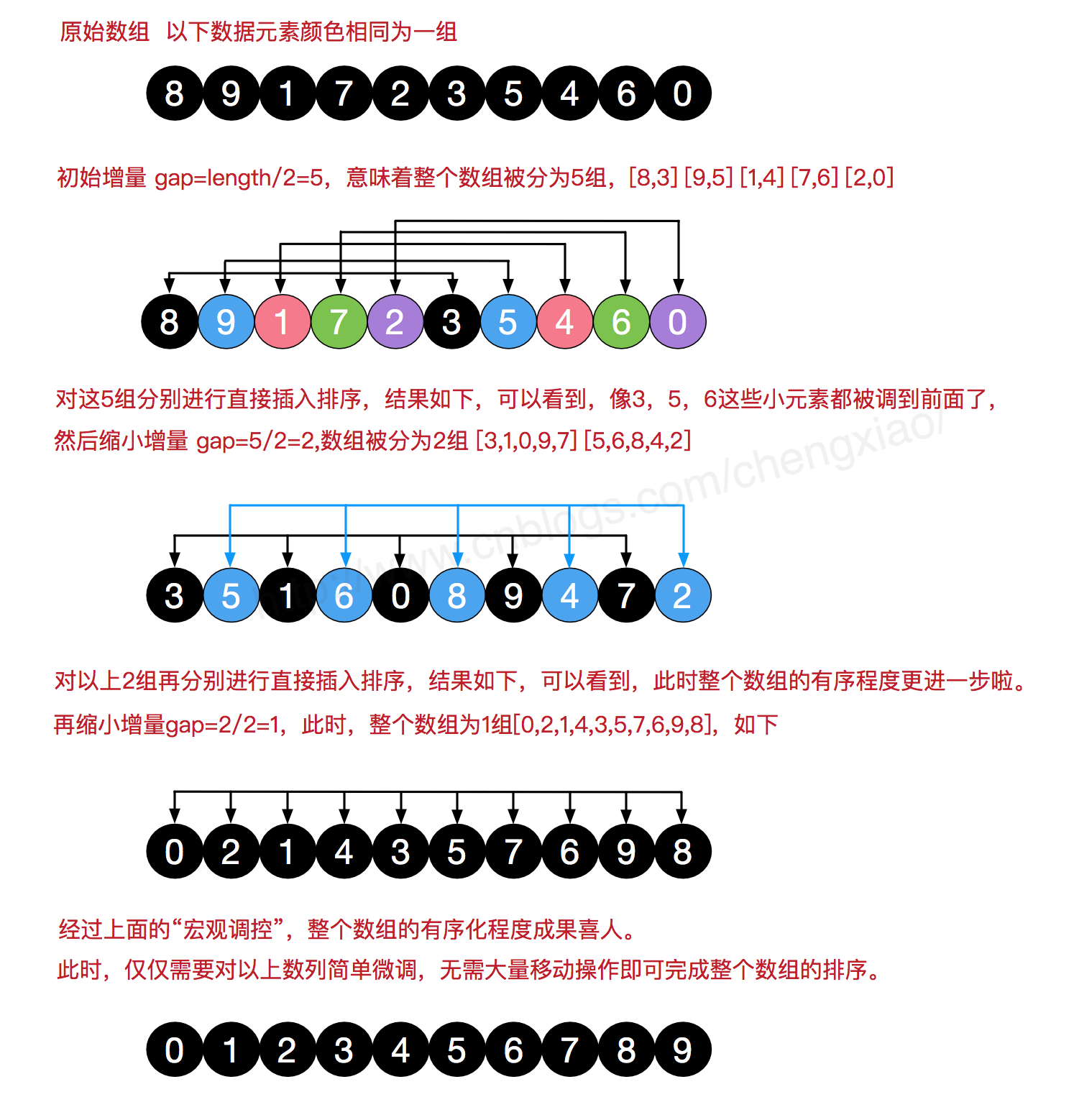
PHP代码实现:
1 | /** |
上述代码的时间复杂度为$nlog^2n$
1 | 复杂度分析过程如下: |
快速排序
快速排序的核心思想是分治法,属于排序效率较高的算法之一
排序步骤:
选取序列中的第一个 元素作为基准元素,比基准元素小的元素排在基准的左边,比基准大的元素排再基准元素的右边,然后将基准两边的元素再分别进行选择第一个元素作为基准,一次递推直到分组仅剩一个元素
PHP代码实现:
1 | /** |
快速排序在处理小规模的数据时(50以下),速度比起插入排序速度较慢,但当数据量比较大的时候,快速排序的优势尤其明显